



AMD Radeon HD 6870/6850评测报告
 每年的第四季度历来是AMD和NVIDIA推出显卡新品的时候,今年也不例外,AMD近就推出了全新的Radeon HD 6000系列显卡,并且推出新品的时间再次领先NVIDIA。但所不同的是,先推出的Radeon HD 6870/6850并不是旗舰级的产品,这让很多人都感到意外。那么,AMD这样做的目的究竟是什么呢?Radeon HD 6870/6850究竟能为我们带来什么?它们的图形架构又有什么变化?
每年的第四季度历来是AMD和NVIDIA推出显卡新品的时候,今年也不例外,AMD近就推出了全新的Radeon HD 6000系列显卡,并且推出新品的时间再次领先NVIDIA。但所不同的是,先推出的Radeon HD 6870/6850并不是旗舰级的产品,这让很多人都感到意外。那么,AMD这样做的目的究竟是什么呢?Radeon HD 6870/6850究竟能为我们带来什么?它们的图形架构又有什么变化?
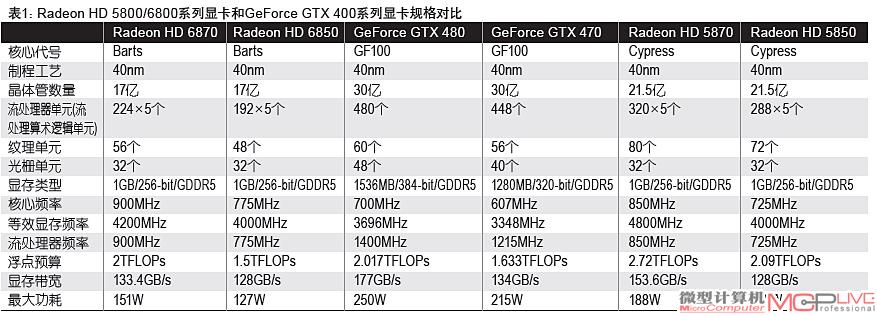
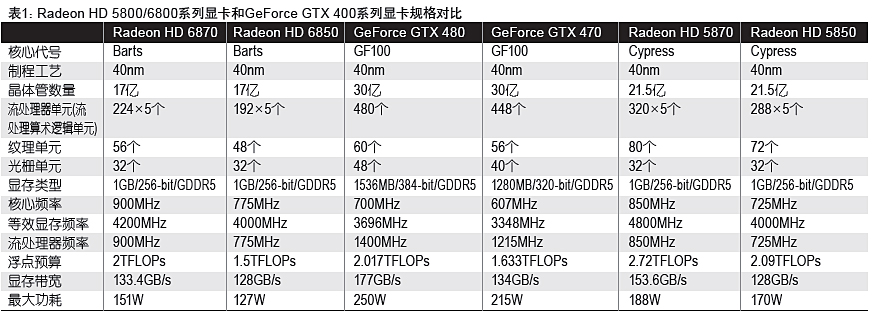
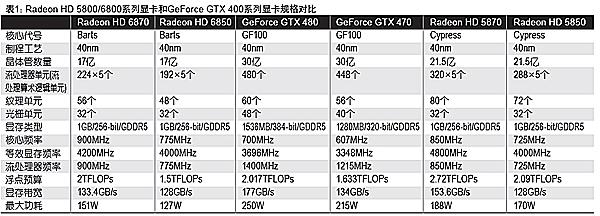
继AMD推出了全新的Radeon HD 5000系列DirectX 11显卡以后,NVIDIA也相继推出了GeForce GTX 400系列显卡。双方你来我往,互有胜负。这种局面在GeForce GTX 460显卡(1399元~1699元)推出以后,开始出现微妙的变化。这款很给力的产品给AMD造成了很大的压力,在这种背景下,新一代Radeon HD 6870/6850适时推出。这次AMD Radeon HD 6800系列显卡采用的图形芯片代号为Barts,它们也是AMD规划的Northern Island”(北岛)图形芯片家族当中早发布的两款产品。

AMD公司原本打算采用TSMC台积电32nm工艺来生产代号为“Northern Island”(北岛)的图形芯片家族,并且按照计划,“Northern Island”图形芯片家族批量供货日期正好符合AMD的新产品发布日期。但由于台积电于2009年底取消了32nm工艺研发计划(相对于40nm,32nm工艺的技术并没有革命性变化,电路设计改动不大,主要是利用光刻技术缩小芯片尺寸),AMD不得不考虑使用现有的40nm工艺来生产Radeon HD 6800系列。终AMD决定针对新一代Radeon HD 6800系列继续采用台积电40nm工艺生产。为此,AMD对原本打算采用32nm工艺生产的Radeon HD 6800系列进行架构上修改,使其更适合台积电40nm工艺,并且尽可能快地上市。因此,从架构上来讲,Radeon HD 6800系列就是Radeon HD 5000系列架构重新平衡的版本,但其中加入了几个关键性的改变。
Radeon HD 6800系列规格和定位解读
就AMD目前公布的数据来看,整个Radeon HD 6000系列已知的研发代号分别为Antilles(安第斯山脉)、Cayman(开曼群岛)、Barts(巴特群岛),它们均是在Radeon HD 5800架构(Cypress)基础上演变而来。其中,Antilles是双核心的旗舰产品;Cayman对应单核心的旗舰产品,地位和Radeon HD 5870一样;Barts则定位高端性价比,目前有两款产品,分别是售价在1899元左右的Radeon HD 6870和售价在1399元左右的Radeon HD 6850。
Radeon HD 6870内建1120个流处理算术逻辑单元(Stream Procesing Unit,SPU)、14组SIMD阵列、56个纹理单元以及32个ROP(光栅处理单元),大浮点计算能力达到了2TFLOPs。该卡搭载1GB/GDDR5/256bit显存,核心频率和显存频率分别为900MHz和4200MHz。根据AMD给出的数据,Radeon HD 6870满载功耗是151W,空载功耗非常小,只有19W。
Radeon HD 6850是Barts系列中仅次于Radeon HD 6870的产品,它内建960个流处理算术逻辑单元(Stream Procesing Unit,SPU)、12组SIMD阵列、48个纹理单元和32个ROP单元,大浮点计算能力达到了1.5TFLOPs。该卡也搭载了1GB/GDDR5/256bit显存,核心频率和显存频率分别为775MHz和4000MHz。根据AMD给出的数据,Radeon HD 6850的功耗稍低,满载功耗是127W,空载仍然保持19W。
Radeon HD 6800系列显卡的定位调整
按照AMD以往显卡命名的特点,Radeon HD X870往往是单核心的旗舰产品,例如Radeon HD 3870/4870/5870;Radeon HD X850往往是单核心次一级的高端产品,例如Radeon HD 3850/4850/5850。而在此次Radeon HD 6800系列显卡中,Radeon HD 6870定位并不是单核心的旗舰产品,而是次一级的高端产品;Radeon HD 6850也并非次一级的高端产品,而是性能更低的产品。

请点击图片,浏览清晰大图。
按照AMD的构想,Radeon HD 6870和Radeon HD 6850并不是替代Radeon HD 5870和Radeon HD 5850的产品,而是作为现有Radeon HD 5800系列的一个补充,整体强于Radeon HD 5700系列,弱于Radeon HD 5800系列。Radeon HD 6870的性能强于Radeon HD 5850,可以将其看成是“Radeon HD 5860”,直接竞争对手是GeForce GTX 470;Radeon HD 6850的性能弱于Radeon HD 5850,可以将其看成是“Radeon HD 5840”,直接竞争对手是GeForce GTX 460 1GB。
另一方面,在Radeon HD 5000系列和GeForce GTX 400系列的推广中,AMD和NVIDIA都无一例外地提到了“Sweet Spot(甜点)”的概念。所谓Sweet Spot主要针对的是游戏玩家,他们的需求是:性能足够优秀,功能尽可能多,发热量和功耗也要控制得好。按照这个需求,千元以下的产品无法胜任,2000元以上的产品性能虽好,但价格太贵,而1399元~1999元的产品则刚好满足玩家的需求,是他们的Sweet Spot。基于这个思路,AMD和NVIDIA在这个价位段上竞争得非常激烈,AMD之前有Radeon HD 5830/5770主打这个价位市场。但随着GeForce GTX 460的出现,情况有所变化。而Radeon HD 6870和Radeon HD 6850的出现从根本上来说,正是为了夹击GeForce GTX 460,全面控制1399元~1999元市场。
关键性的架构改变:Barts图形架构解读
承袭Radeon HD 5800系列的SIMD架构Barts仍然采用AMD惯用的SIMD(单指令多数据流)架构,这部分架构和Cypress保持一致,即80个SP单元构成1组SIMD阵列。在Barts的1组SIMD阵列当中,L1缓存容量和纹理单元仍然和Cypress保持一致,即16KB L1纹理缓存,8KB L1计算缓存和4个纹理单元。

Barts的核心架构
在微架构层级上,AMD继续采用32个ROP设计,结合Barts的高频率,使其相比Cypress更有优势。和ROP连接的是L2缓存和内存控制器,L2缓存由4个128KB区块组成,总计512KB二级缓存。同时,4个64bit内存控制器让Barts的显存位宽达到256bit。值得一提的是,Barts使用了Redwood(Radeon HD 5600/5500系列)的GDDR5显存控制器,因此显存频率只有4200MHz。而Cypress/Juniper(Radeon HD 5800/5700系列)的显存控制器则可以运行在4800MHz。这样的好处是Barts的显存控制器尺寸比Cypress减小了50%左右,从而减小了核心面积。
但值得注意的是,AMD在Radeon HD 6870显卡设计之初,曾经拿出2个设计方案,一个是16 SIMD(1280 SP)+16 ROP的设计,另外一个是14 SIMD(1120 SP)+32个ROP的设计,也就是我们目前看到的设计,后者在性能上更快,但是领先幅度很小。不过考虑到从Cypress架构移植的简便性和成本等因素,AMD终选择了14 SIMD(1120 SP)+32个ROP的设计。
仍然采用VLIW5设计
与Radeon HD 5000系列一样,Barts在SPU(流处理算术逻辑单元)中,继续采用AMD的VLIW5(超长指令字5)设计,具备5个流处理器算术逻辑单元(W、X、Y、Z、T单元)、1个分支单元和一组GPR单元协同工作来处理指令。其中,W、X、Y、Z这四个简单的SPU单元一起工作,在一个单位时钟周期内可以处理4个FP32 MAD运算,而T(SFU)单元可以像其它四个单元那样处理FP32计算,或者负责处理诸如超越指令等特殊功能。
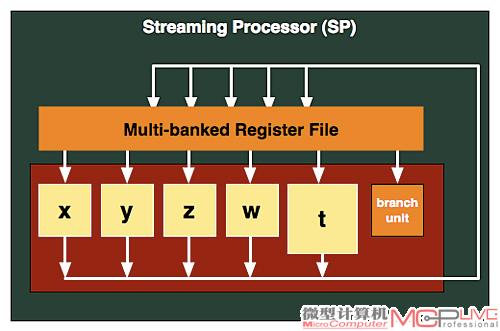
Barts的SP单元架构
总体而言,1个SPU单元在1个时钟周期可以完成的工作是4次32bit浮点MAD运算和4次24bit整数乘法或者加法运算,SFU单元在1个时钟周期内可以完成的工作是1次32-bit浮点MAD运算。

Barts的SIMD核心架构
和Cypress相比,AMD没有公布Barts的FP64性能数据。这并不是AMD的疏忽,因为Barts并不属于旗舰级的产品,旗舰级的产品是于2010年11月底发布的Radeon HD 6900系列。因此,AMD省略了Barts的FP64功能,以便缩小芯片面积,进一步降低生产成本。这也是1399元~1999元价位产品的常见做法。
增强的线程分配模块设计
这样看来,Radeon HD 6800系列相比Radeon HD 5800系列在规格上并没有明显提升,反而不升反降。那么Radeon HD 6800系列的提升和改变究竟在哪里呢?答案是增强的线程分配模块设计。凭借这一设计,Radeon HD 6800系列提升了SPU的执行效率,简单说,SPU数量虽然减少了,但是效率反而提升了。
在介绍这个功能之前,我们不妨先来看看Fermi和Cypress在图形架构上的差异。Barts仍然沿用AMD一贯的SIMD单指令多数据流架构,而Fermi则沿用了MIMD多指令多数据流架构。对Fermi而言,诸如曲面细分单元、指令分配器等功能单元都整合在单独的GPC图形处理器集群里面。在每个GPC里面都整合了一个曲面细分单元,完整的GF100核心具备16个曲面细分单元,曲面细分功能出色。由于功能完整,我们甚至可以将GPC看成是一个可以独立运行的GPU。
而Barts则不同,它具备一个Command Processor(命令处理单元),内含一个曲面细分单元和一个Ultra-Threaded Dispatch Processor(超线程分派器)等功能单元。Command Processor的主要作用是进行指令线程分配工作,而Ultra-Threaded Dispatch Processor负责将处理过的数据进行重新整理过滤,为每个着色类型进行分类,分配SC运行相应的渲染程序。但Command Processor并没有整合在每组SIMD阵列中,而是所有的SMID阵列共享一个Command Processor。换句话说,Cypress只有一个曲面细分单元和一个线程管理单元,因此曲面细分性能和线程管理能力并不特别出色。
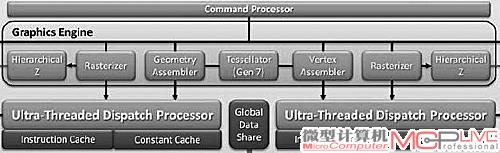

和Cypress(上)不同,Barts(下)增加了Ultra-Threaded Dispatch Processor的数量。
对SIMD架构来说,其可以一定程度提高运算效率,能够在现有工艺下实现SPU的大化(Radeon HD 5870就具备1600个SPU)。不过它必须依靠外部的指令线程分配工作。在指令线程发送到SP时,线程被分成波前(Wave Front)组,每个波前包含64个线程。为了大限度地利用GPU的使用率,线程需要被合理组织起来,以保证在每个时钟周期单条指令的情况下满足一个SP中5个SPU的需求。如果指令没有满足5个SPU当中的任何1个的需求时,都将影响到芯片性能。在DirectX 11游戏中,曲面细分功能被引入后,会产生更多的并行线程和指令,更加考验线程管理器在分配每个SPU的计算和为着色类型进行分类的能力。
在这种背景下,Cypress虽然拥有夸张的SPU数量,但由于线程分配模块数量少,执行效率在一些游戏场景中不高,甚至还遇到了瓶颈,一个Ultra-Threaded Dispatch Processor已经不能满足需求了。因此在Barts架构中,AMD引入了两个Ultra-Threaded Dispatch Processor(指令缓存也翻倍),有力地提升了SIMD的工作效率。
AMD对曲面细分计算性能的态度
上面我们已经提到,Barts引入了两个Ultra-Threaded Dispatch Processor,大幅提升了SIMD的执行效率。此外,它还带来了另一个好处,那就是也提升了Barts的曲面细分计算性能。
在AMD看来,Barts的曲面细分计算性能已经能够很好地适应当下DirectX 11游戏的需求了。AMD认为在当前的DirectX 11游戏中,将一个物体细分后小的像素在16个是比较合适的,因为他们相信这能反映曲面细分在游戏当中的应用。当小像素超过16个以后,肉眼也无法察觉出来。
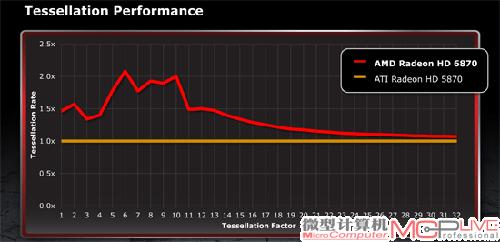
AMD给出的Radeon HD 6870和Radeon HD 5870曲面细分性能对比
从上图AMD自己的测试结果来看,Radeon HD 6870的曲面细分性能达到Radeon HD 5870的2倍区间当中,曲面细分小的像素在6个~10个(小像素为6个时,Radeon HD 6870的曲面细分性能达到达到高)。小像素在6个以下或者达到13个的时候,Radeon HD 6870的曲面细分性能大约是Radeon HD 5870的1.5倍左右。随着小像素数量的增加,Radeon HD 6870的曲面细分性能越来越接近于Radeon HD 5870。在小像素达到32个之后,两者的曲面细分性能更加接近。凭借较高的工作频率,Radeon HD 6870的曲面细分性能小幅领先。这意味着,Radeon HD 6870曲面细分性能改善仅局限于曲面细分小的像素较少的情况下,一旦小像素的数量大幅度提升,Radeon HD 6870的曲面细分性能就会因超大规模三角形细分而大量耗费资源,从而造成性能下降。
需要说明的是,虽然Radeon HD 6800系列的曲面细分单元仍然只有一个,但其已经升级为增强型的Tessllator Gen7,一定程度增强了曲面细分能力。但我们应该认识到,Barts曲面细分计算性能的主要提升并不是来源于曲面细分单元的优化或者数量的提升,而是来源于线程分配模块的增强。不过这只能治本,却无法治标。因此在高负荷曲面细分计算环境下,Barts的曲面细分性能会大幅下降,此时即使拥有增强的线程分配模块设计也起不了太大的作用,因为主要的瓶颈在曲面细分单元的数量和效率上。
Radeon HD 6800系列性能测试
接下来我们将进入精彩的性能测试部分,你将了解到Radeon HD 6800系列真实的游戏、曲面细分性能和功耗温度方面的表现,以及它和Radeon HD 5800、GeForce GTX 400系列之间的对比。图形架构经过改良以后的Radeon HD 6800系列的游戏性能究竟怎样?Radeon HD 6800的SPU数量减少后,究竟会对游戏性能造成多大的影响?它的曲面细分性能能否有一定的提升?我们将组建基于AMD Phenom Ⅱ X6 1090T的顶级3A游戏平台进行测试,带给你详细和真实的的测试结果

请点击图片,浏览清晰大图。
首先是DirectX 10/10.1游戏和软件,我们将用《3DMark Vantage》、《孤岛危机》等热门DirectX 10/10.1的游戏和软件对Barts的DirectX 10/10.1性能进行测试。对DirectX 11显卡而言,它的DirectX 11性能才是大家为关心的话题。为此,我们将选取《地铁2033》、《异形大战铁血战士》等多款DirectX 11游戏(均运行在高画质下)和软件重点考查Radeon HD 6800系列在DirectX 11游戏和软件中的性能,看看它们的DirectX 11执行效率究竟有没有提升?此外,我们还将重点考察Radeon HD 6800系列的抗锯齿性能和交火性能。
由于Radeon HD 6800系列在图形架构上为Tessellation做了一定程度的优化,Tessellation性能会有一定程度的增长,我们将通过《Unigine Heaven Benchmark 2.0》这款DirectX 11软件来重点验证它的几何性能。《Unigine Heaven Benchmark》是首款支持DirectX 11的基准测试软件,类似于3DMark系列软件。该软件的测试场景中包含了大量基于Tessellation的测试画面,可以深度考查显卡的Tessellation性能。在该软件的测试中,“DirectX 11+Shader(High)+Tessellation(Extreme)”表示显卡运行在高画质、极致Tessellation等级的DirectX 11模式下,这是考验显卡在极致Tessellation画面下的性能。
测试平台
| CPU | AMD AMD Phenom Ⅱ X6 1090T |
| 主板 | 华硕CROSSHAIR Ⅳ EXTREME |
| 内存 | 金邦DDR3 1600 2GB×2 |
| 电源 | 航嘉X7 900W |
| 系统 | Windows 7旗舰版64bit |
DirectX 10测试
●Radeon HD 6870/6850 Vs. GeForce GTX 470/460 1GB
和GeForce GTX 470相比,Radeon HD 6870的综合性能稍占优势,主要体现在《孤岛危机》中,领先幅度在14%左右。不仅仅是Radeon HD 6870,Radeon HD 6850和Radeon HD 5800系列都在这款游戏中获得了不错的成绩,这是因为这款游戏使用了大量高精度和复杂的贴图,A卡在纹理单元数量和效率上的优势体现出来。虽然和Radeon HD 5870相比,Radeon HD 6870的纹理单元数量下降,但图形架构得到了优化,使得其游戏性能有不错的表现。和Radeon HD 6870的情况类似,Radeon HD 6850的纹理贴图和3D渲染能力表现也不俗。
●Radeon HD 6870/6850 Vs. Radeon HD 5870/5850
和老大哥Radeon HD 5870/5850相比,Radeon HD 6870/6850由于在图形架构上做了重要优化,使用了两个Ultra-Threaded Dispatch Processor,使得其在SPU、纹理单元数量下降的情况下,游戏性能并没有明显损失,甚至在《孤岛惊魂2》中,Radeon HD 5870和Radeon HD 6870的性能差距已经微乎其微了。另一方面,能取得这样的优势也得益于Radeon HD 6870的超高核心频率,900MHz的频率是以往AMD公版产品不曾具备的频率,这在一定程度上弥补了SPU数量的降低。
DirectX 11测试
●Radeon HD 6870/6850 Vs. GeForce GTX 470/460 1GB
在DirectX 11游戏的测试中,Radeon HD 6870/6850和GeForce GTX 470/460 1GB的性能对比情况和DirectX 10游戏类似。只是Radeon HD 6870/6850的领先幅度被缩小了,它们的性能基本和GeForce GTX 470/460 1GB持平。在DirectX 11游戏中,GeForce GTX 470/460 1GB之所以拥有不错的游戏性能在于它们的图形架构专为DirectX 11游戏进行了优化,特别是在那些具备大量曲面细分的游戏中,GeForce GTX 470/460 1GB的优势会更明显一些。
相对于GeForce GTX 470/460 1GB,Radeon HD 6870/6850的主要优势体现在《战地:叛逆连队2》和《异形大战铁血战士》中。考虑到GeForce GTX 470/460 1GB的售价(分别为2399元和1699元左右),Radeon HD 6870/6850的性价比优势还是比较明显的。
●Radeon HD 6870/6850 Vs. Radeon HD 5870/5850
相对于Radeon HD 5870/5850,Radeon HD 6870/6850在DirectX 11游戏的测试中,继续着强势的表现,SIMD的执行效率较高的优势得到了进一步体现。这主要体现在具备大量曲面细分的游戏中,Radeon HD 6870/6850在Ultra-Threaded Dispatch Processor数量上的优势被展现出来,GPU在处理多个线程和指令的时候,很好地为每个SPU的着色和计算进行了分配,弥补了SPU数量不占优势的缺点。
在《尘埃2》、《失落的星球2》测试中,Radeon HD 6870的性能甚至已经超越了Radeon HD 5870。但和Radeon HD 5850相比,SPU、纹理单元数量都不占优势的Radeon HD 6870却全面胜出,这进一步体现了Radeon HD 6870在架构上的优化。
正如Radeon HD 6850定位弱于Radeon HD 5850那样,Radeon HD 6850在所有DirectX 11游戏测试中,小幅落后Radeon HD 5850。但整体落后幅度不大,保持在15%左右。
抗锯齿性能提升不明显
尽管AMD在Radeon HD 6800系列上引入了全新的MLAA抗锯齿模式,理论上,它的抗锯齿性能应该有所提升。但可能是因为驱动的问题,我们无法在游戏中开启MLAA模式,因此只能在既有的抗锯齿模式下进行测试,这导致Radeon HD 6800系列的抗锯齿性能提升并不明显。


这是《Unigine Heaven benchmark 2.0》8xMSAA模式(左)和MLAA画质(右)对比,我们可以看到在8xMSAA情况下,画面右侧栏杆和左侧半球形房顶焊接处还是存在明显锯齿,而MLAA的情况则好不少。对比画面,MLAA的反锯齿效果更好。但正如我们在技术解析部分所说那样,MLAA存在反锯齿低点误判的问题。因此对比8xMSAA和MLAA画面,我们可以发现,不少无需进行反锯齿处理的地方存在轻微的色彩发黑现象,这就是MLAA错误的反锯齿地点,这是将对比度不同的像素混合所造成的。
以Radeon HD 6870为例,它在开启了抗锯齿以后,总体性能下降幅度在30%左右,性能损失幅度和Radeon HD 5870基本持平。例如在《潜行者:普里皮亚季》中,Radeon HD 6870开启抗锯齿后的性能下降幅度为45%,而Radeon HD 5870为43%;在《失落的星球2》中,Radeon HD 6870和Radeon HD 5870的性能下降幅度分别为19%和24%。相信等新版驱动发布以后,问题可以得到改善。
曲面细分计算性能有所提升
在AMD看来,在当前的DirectX 11游戏中,将一个物体细分后小的像素数量为16个是比较合适的。这也暗示了Radeon HD 6800系列在高负载的曲面细分环境下的曲面细分性能损失将会很大,《Unigine Heaven Benchmark》的测试结果验证了这一点。在1920×1080+DirectX 11+Shader(High)+Tessellation(Extreme)设置下,GeForce GTX 470领先Radeon HD 6870 42%。而GeForce GTX 460 1GB的曲面细分单元数量较GeForce GTX 470而言,减少至7个,因此曲面细分性能有所下降。和它相比,Radeon HD 6870虽然只有1个曲面细分单元,但曲面细分性能反而领先它4%。由此可见,增强的线程分配模块设计大幅提升了Radeon HD 6870的曲面细分性能。值得一提的是,和Radeon HD 5870相比,Radeon HD 6870的曲面细分性能仍然处于领先水平,领先幅度为8%,这让我们对Radeon HD 6870的曲面细分性能刮目相看。
交火性能基本满意
在交火测试中,Radeon HD 6870 CrossFireX的交火性能基本令人满意,例如在《Unigine Heaven Benchmark》、《失落的星球2》、《异形大战铁血战士》、《地铁2033》和《3DMark Vantage》中,Radeon HD 6870 CrossFireX的交火性能都达到或者接近100%,表现非常出色。即使在《潜行者:普里皮亚季》中,其性能提升幅度也达到了50%左右。但在余下游戏中,Radeon HD 6870 CrossFireX的表现就不那么优秀了,例如在《孤岛危机》中的性能提升幅度只有25%左右,还需要后续驱动的完善。总的来看,Radeon HD 6870 CrossFireX的效率还是比较高的。
功耗和发热量占据绝对优势
对功耗和发热量的控制一直是Radeon HD 5000系列的优势,Radeon HD 6800系列也延续了这种表现,特别是在架构精简的情况下,这种优势更加明显。Radeon HD 6870的满载系统功耗为288W,分别比Radeon HD 5850和GeForce GTX 470低了8W和80W。Radeon HD 6850的满载系统功耗为249W,分别比Radeon HD 5850和GeForce GTX 460 1GB低了47W和21W。在温度表现方面,Radeon HD 6850的待机温度和满载温度分别为35℃和71℃,Radeon HD 6870则分别为38℃和83℃,温度表现也令人满意。
首批上市的Radeon HD 6800系列显卡一览
迪兰恒进HD6870

| 核心频率 | 900MHz |
| 显存频率 | 4200MHz |
| 参考价格 | 1899元 |
迪兰恒进HD6850恒金版1GB

| 核心频率 | 775MHz |
| 显存频率 | 4000MHz |
| 参考价格 | 1299元 |
镭风HD6870龙蜥版1024M D5

| 核心频率 | 900MHz |
| 显存频率 | 4200MHz |
| 参考价格 | 1899元 |
蓝宝石HD6870 1GB GDDR5

| 核心频率 | 900MHz |
| 显存频率 | 4200MHz |
| 参考价格 | 1999元 |
蓝宝石HD6850 1GB GDDR5

| 核心频率 | 775MHz |
| 显存频率 | 4000MHz |
| 参考价格 | 1399元 |
华硕EAH6870

| 核心频率 | 900MHz |
| 显存频率 | 4200MHz |
| 参考价格 | 待定 |
盈通R6870-1024GD5豪华版

| 核心频率 | 900MHz |
| 显存频率 | 4200MHz |
| 参考价格 | 1899元 |
Radeon HD 6800系列:新一代高端性价比王者
我们曾经对Radeon HD 5800系列做出如下评价:它是在RV770图形架构基础上,通过大量增加SPU数量和一些局部改变而得到的产品,新增了诸如源码输出等功能,是当时的单核心王者,功耗和发热量出色。现在,这句话的部分描述仍然适用于Radeon HD 6800系列:它是在Cypress图形架构基础上,做了一些局部调整,新增加了HD3D、新的宽域技术、MLAA抗锯齿、UVD3.0等新功能,功耗和发热量出色,是新一代高端性价比王者。但细心的你已经注意到了它们之间的区别:SPU数量和性能定位。看似不起眼的两个变化却深刻体现了Radeon HD 6800系列在设计理念上的变化和思路。
首先是SPU数量上的变化,Radeon HD 5870的SPU达到了空前的1600个,浮点运算更是达到了夸张的2.72TFLOPs,是当时浮点运算强的显卡。通过这种大幅甚至激进的设计方式,Radeon HD 5870的确也获得了不错的3D性能。但当大量DirectX 11游戏特别是具备大量曲面细分计算的DirectX 11游戏出现以后,显卡需要处理更多的线程和指令,Radeon HD 5870开始力不从心,暴力堆积SPU的方法似乎不再那么管用了。虽然它依靠SIMD架构使SPU达到了1600个,但如此庞大的单元在面对日益复杂的指令和越来越多的线程时,却遇到了一些瓶颈—如何更好地对这1600个SPU的计算和着色进行分配,使其执行效率更高呢?这成为AMD设计人员必须考虑的问题。
在Radeon HD 6800系列上,他们找到了问题所在,并努力地改善和解决:不再暴力堆积SPU并缩减一定比例的SPU,通过增强线程分配模块来提升SPU的执行效率,进而提升曲面细分计算的性能,并通过更新的工艺提升Radeon HD 6870的核心频率,从而全面提升它的纹理、光栅和曲面细分性能。可以看出,不再过分强调SPU数量,更多地对线程分配模块进行优化以提升其分配管理能力,并适当加入曲面细分模块数量将是AMD下一代图形架构着力改善的地方。
其次是产品定位的问题,AMD和NVIDIA都看到了1399~1999元的产品才是玩家热衷的“Sweet Spot”,因此AMD打算针对这个价位,先推出基于新一代Radeon HD 6000系列的Radeon HD 6870/6850显卡,为整个Radeon HD 6000系列造势。Radeon HD 6870的性能介于Radeon HD 5870/5850之间,它通过缩减SPU数量,努力缩减芯片面积(255平方毫米),减少成本,并改善SPU利用效率,进而达到不错的表现。这就是Radeon HD 6800系列成为玩家喜爱的Sweet Spot的秘密。
再者,从产品性能来看,Radeon HD 6870/6850基本完成了各自的既定目标,它们与GeForce GTX 470/460 1GB的性能互有胜负,性能基本持平。但考虑到GeForce GTX 470/460 1GB的售价(分别在2399元和1699元左右),以及Radeon HD 6870/6850具备的低功耗和低发热量,Radeon HD 6870/6850的性价比优势就显现出来了。
再进一步分析Radeon HD 6870/6850这对双子星会发现,其实它们的出现还有一个深层次的目的,那就是遏制对手NVIDIA的Sweet Spot战略的重要武器,GeForce GTX 460 1GB。因为市场上热卖的并不是GeForce GTX 470(货源很少),而是GeForce GTX 460 1GB。和GeForce GTX 460 1GB相比,Radeon HD 6870的性能有较大优势,但价格只贵了几百元,且随时有调价的可能;而Radeon HD 6850性能虽然与之持平,但却有价格上的优势,向下还可以直接威胁GeForce GTX 460 768MB。可以预见,在未来一段时间内,Radeon HD 6870/Radeon HD 6850这对组合拳轮番出拳会使GeForce GTX 460比较难受。截至发稿前,NVIDIA已经对新推出的Radeon HD 6800系列做出回应:将GeForce GTX 470的建议零售价调到1999元。
后,我们再对AMD和NVIDIA即将发布的产品做一个预览,代号分别为Cayman XT和Cayman Pro的单核心顶级产品和单核心次顶级产品Radeon HD 6970和Radeon HD 6950即将发布,接下来代号为Antilles的双核心顶级产品Radeon HD 6990也将发布。当然,NVIDIA也没闲着,新一代GeForce GTX 580也即将发布。真正的卡皇较量即将开始!
更多有关Radeon HD 6800系列显卡的内部大图,请浏览网站其他栏目。
AMD Radeon HD 6800系列特色功能解析
在上一篇Radeon HD 6800系列的评测文章中,我们对其的游戏性能和图形架构有了全面的认识。下面,我们将进一步来了解Radeon HD 6800系列(Barts)的图形架构。
高画质:AMD修正纹理过滤、加入形态反锯齿
在Radeo HD 5800系列中,AMD引入了角度独立的各向异性过滤技术,极大地改善了各向异性过滤过滤依赖角度的问题,特别是Radeon HD 4000系列相对低下的各向异性过滤画质。随后NVIDIA发布了GeForce GTX 480,外界一直认为很难在两者之间发现各向异性过滤上的画质差别。不过,一款赛车游戏《Trackmania》却揭示出Radeon HD 5800系列显卡在各向异性过滤上的存在的问题。
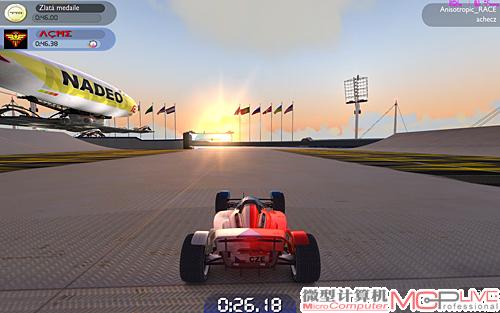
Radeon HD 5800系列在赛道Mipmaps上的过渡比较生硬,层次感过于强烈。
这是因为Radeon HD 5800系列在处理纹理过滤当中的确存在问题,特别是在处理所谓有复杂固定特征的“嘈杂”纹理当中。AMD的纹理过滤算法没有正确地混合这些纹理Mipmaps之间的过渡。
在Radeon HD 6800系列上,AMD已经改进纹理过滤算法,以更好地处理这种情况。现在Radeon HD 6800系列可以正确地过滤高规律纹理,消除它们之间可见的转换。不过,目前我们还无法对角度独立的各向异性过滤进行性能损失测试,因为目前还没有找到打开和关闭角度独立各向异性过滤算法的办法。
下面我们来看看Barts的反锯齿技术。自从NVIDIA发布GeForce GTX 400系列以来,AMD在5800系列上的反锯齿优势已经消失。GeForce GTX 480当中除了使用CSAA覆盖样本进行Alpha To Coverage采样之外,还为DirectX 10游戏首度引入透明超级采样模式,因此它在一些重锯齿游戏当中有比较明显的优势,而透明超级采样反锯齿也可以用较小性能损失消除掉游戏当中的大部分锯齿。
针对GeForce GTX 480的反锯齿技术进步,AMD在Barts当中引入一个全新的反锯齿模式,即Morphological Anti-Aliasing(MLAA,形态反锯齿)。
简单来说,MLAA是一个后处理反锯齿过滤。传统反锯齿模式都是在画面完成渲染之前进行,比如MSAA多重采样反锯齿是对多边形边缘进行处理,即便是NVIDIA的透明超级采样反锯齿也需要知道Alpha覆盖纹理的位置才能工作。而MLAA是在图像渲染完成之后才对图像进行反锯齿处理,无需知道图像渲染过程。具体来说,MLAA寻找高对比度界线的某些类型,一旦找到这些类型,MLAA将它们视为锯齿假影,并且将周围的像素混合,以降低对比度从而达到消除锯齿的目的。由于MLAA是后处理反锯齿过滤,因此无论是延迟渲染、Alpha纹理等所有特殊场合,MLAA都能胜任反锯齿工作,即便是锯齿较明显的《战地:叛逆连队2》,MLAA都可以很好地消除锯齿。AMD表示MLAA反锯齿速度也很快,速度不会低于AMD的边缘侦测反锯齿(EDAA)模式。
其实,MLAA并非全新反锯齿技术,但是在PC显卡上应用还是头一遭。MLAA早已经在游戏机当中得到应用。MLAA让游戏机以廉价方式执行反锯齿,无需MSAA反锯齿所需的高内存带宽。实际上,MLAA是一种全方位的廉价反锯齿方法,因为它也无需太多的计算时间。
不过美中不足的是,MLAA是一种后处理过滤,并非真正意义上的反锯齿技术,无法在图像渲染过程当中进行反锯齿处理。传统反锯齿技术使用渲染数据来精确判断在何时何地,以何种方式进行反锯齿处理,而MLAA只能依靠对渲染后图像的对比度来决定反锯齿的程度,因此在反锯齿上难免存在误差,即有可能对不需要进行反锯齿的地方进行反锯齿,这就导致边缘画质清晰度上不如MSAA和SSAA。总体而言,SSAA目前能提供好的反锯齿画质,MSAA等反锯齿次之。
此外,AMD在Barts当中通过驱动程序调用DirectCompute着色来完成MLAA。MLAA也充分利用到Barts SIMD设计的本地数据存储优势,在显存当中存储需要调整的像素信息,以加速MLAA过程,这也是MLAA性能开销较低的原因。既然MLAA是一个计算着色过程,那么MLAA也应该向下兼容Radeon HD 5000系列。尽管AMD还没有承认这点,但已经有Radeo HD 5000系列显卡用户通过修改注册表的办法,在催化剂10.10c驱动程序配合下成功实现MLAA。
着眼未来:升级的宽域技术
Barts尽管在架构上变化不大,但其内部大部分二级控制器均有改动修正和提升。和Cypress相比,几乎所有涉及显示和视频解码的部分均已经经过修改和升级,比如Barts开始支持DisplayPort 1.2标准。
AMD在Radeon HD 5000系列显卡中首次引入DisplayPort接口。同时,AMD在Eyefinity宽域技术当中也引入DisplayPort标准。按照DisplayPort标准,当一块Radeon HD 5000系列显卡同时驱动6台显示设备的情况下,无需为每个显示设备都配备独立的时钟频率发生器。因此,我们也就不难理解为什么AMD在DisplayPort研发上投入巨资,并且在DisplayPort 1.2标准制定完毕不到一年时间,Barts就开始支持新一代DisplayPort标准。Radeon HD 6800系列是首批支持DisplayPort 1.2标准的显卡产品。
那么DisplayPort 1.2标准能为Barts带来什么好处呢?从技术层面上看,DisplayPort 1.2标准规定的带宽是DisplayPort 1.1标准的2倍,另外还加入一些新功能。AMD正在将DisplayPort 1.2标准融入到全新的宽域技术当中,即一个端口可以驱动多台显示设备。具体来说,1个DisplayPort 1.2链接的带宽足够以60Hz的刷新率驱动两台2560×1600分辨率的显示设备,或者4台1920×1080分辨率的显示设备。
另外,DisplayPort是一种基于分组的传输介质,它很容易扩展其功能,因为它只需要知道如何处理传输给它的数据包即可。因此,DisplayPort 1.2标准采用Multi-Stream Transport(多流传输,MST)来定义多显示设备支持。MST顾名思义,是利用DisplayPort 1.2带宽,通过将几个显示流交织成1个DisplayPort 1.2流进行封包,每个显示设备都对应1个完全独立且独特的显示流。
与此同时,在接收端有两种方式来处理MST,菊花链方式和集线器方式。其中,菊花链方式指DisplayPort 1.2显示设备依次连接,MST流在这些设备上依次传输。不过除了预制的多显示设备,菊花链方式不大可能得到广泛应用,因为菊花链方式需要DisplayPort 1.2规格显示设备,并且设置工作相对麻烦。
替代菊花链的方法是使用1个DisplayPort 1.2 MST集线器,用于拆分客户端设备之间的信号。DisplayPort 1.2 MST集线器是一种智能设备,可以像USB集线器那样主动处理信号,而非如网线集线器那样只是单纯地传输信号。采用DisplayPort 1.2 MST集线器的好处显而易见,用户无需专门购买DisplayPort 1.2规格的显示设备,因为DisplayPort 1.2 MST集线器已经承担起分离显示流和显示设备进行交流的工作。另外,DisplayPort 1.2 MST集线器兼容适配器,这意味着通过合适的主动式适配器,DisplayPort 1.2 MST集线器就可以创建DVI/VGA/HDMI接口,让没有多余空间集成多个输出接口的设备也可以驱动多台显示设备。

菊通过HUB或者菊花链显示,单个接口可以支持多个显示器。
和Cypress一样,Barts也能同时驱动6台显示设备。但是和Cypress不同,因为有DisplayPort 1.2 MST集线器帮忙,AMD无需再推出Barts版的6个Mini DisplayPort接口产品。现在一块Barts显卡只集成两个Mini DisplayPort接口,借助两台DisplayPort 1.2 MST集线器,即可同时驱动6台显示设备,即所谓“3+3”模式,让6屏显示配置更加便捷。
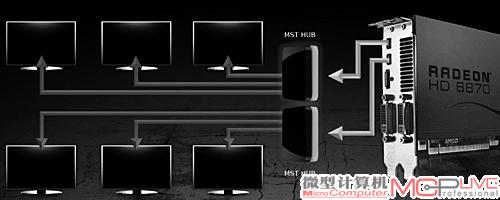
一块Radeon HD 6870显卡通过2个DisplayPort 1.2 MST集线器同时驱动6个显示设备
但是,AMD现在是第一个吃螃蟹的厂商,上述构想仍限于纸面,因为诸如DisplayPort 1.2 MST集线器和DisplayPort 1.2规格的显示设备要2011年左右才能上市。

Barts的接口配备
现在借助DisplayPort 1.2巨大的传输带宽,AMD也得以适时推出全新的3D立体技术—HD3D。HD3D与NVIDIA 3D Vision的实现原理类似,在硬件层面上都要求显示设备具备120Hz的刷新率。HD3D属于开放的3D解决方案,可以很好地和其他3D设备兼容。HD3D目前没有属于自己的3D眼镜方案,因此在使用HD3D技术时,需要使用第三方的3D显示器和眼镜。由于HD3D才发布,因此其在业界的知名度还不及NVIDIA 3D Vision,但AMD表示HD3D支持目前主流的3D设备和软件,未来的发展看好。
功能扩展:HDMI 1.4a、UVD3和显示校正
AMD在Barts当中不仅改进了DisplayPort控制器,而且也改进了HDMI控制器。之前,Cypress支持HDMI 1.3规范,现在Barts可以支持HDMI 1.4a规范。借助HDMI 1.4a,AMD现在可以支持全分辨率(1080p)的3D立体电影,720p的3D游戏和其它要求单眼60Hz刷新率的应用,即它可以支持目前新上市的3D显示设备,如电视机和投影仪等。
Barts支持1080p的3D立体电影需要内部专门的解码单元配合,这就是UVD3或者称之为第三代统一视频解码器。近一次UVD获得重大升级还是在UVD2的时候,UVD2和Radeon HD 4000系列一起发布,AMD把IDCT和动态补偿功能从GPU着色器迁移到UVD固定硬件电路,让UVD2部分支持MEPG-2硬件解码。
和UVD2一样,UVD3包含UVD现有功能集,另外添加对3个编解码器支持:MPEG-2、MVC和MEPG-4 ASP(即DivX/XviD)。UVD和UVD2无法对MEPG-4 ASP进行硬件解码,完全交给CPU以软件方式进行解码。现在借助UVD2,MPEG-4 ASP解码可以完全交给GPU来完成。
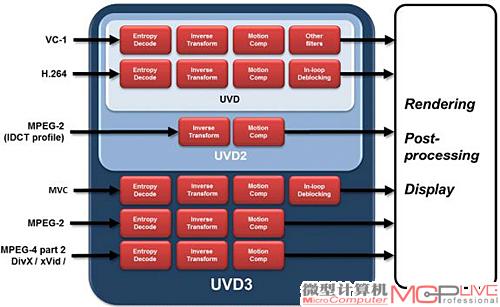
UVD3的架构
对MEPG-4 ASP进行硬件解码的功能并不是Barts首创,NVIDIA在GeForce GT 210/220上就引入了类似功能。尽管AMD在时间上有稍许落后,但AMD将以更多的软件支持来弥补时间上的差距。AMD携手DivX发布了1个beta版DivX编解码器,支持UVD3对MPEG-4 ASP进行硬件解码。此外,AMD在Barts驱动程序和未来版本催化剂当中将他们的MPEG-4 ASP性能充分展示和曝光。
不过现在唯一的缺点是,尽管微软更加重视Windows 7操作系统内建的编解码器,但Windows 7遇上DXVA加速的MPEG-4 ASP视频还是不知道该如何处理。虽然Windows 7能以软件方式播放MPEG-4 ASP,但是用户仍然需要诸如DivX等第三方编解码器,获得MPEG-4 ASP的硬件解码。
另外值得一提的是,AMD在Radeon HD 6800系列当中引入MPEG-4 ASP硬件解码,就如同支持HDMI 1.4a那样,对主流PC平台来说,并非相当重要,因为MPEG-4 ASP是1个轻量级的编解码器。但如果AMD明年的APU产品,比如Bobcat内建UVD3的话,就比较有意思了,因为MPEG-4 ASP软件解码对低端CPU来说还是比较费劲的。
UVD3现在也支持完全的MPGE-2硬件解码,尽管MPEG-2已经非常古老,并且比MPEG-4 ASP更容易解码。尽管过去十年当中,GPU已经支持MPEG-2解码加速,但是CPU性能异军突起,CPU和GPU的硬件解码加速底层(反向离散余弦变换)结合,对付MPEG-2解码已经绰绰有余。但是,AMD在这些年当中,除了在UVD2把iDCT/运动补偿从GPU shader迁移到UVD2固定电路当中之外,在MPEG-2硬件解码上没有更多作为。
因为MPEG-4 ASP和MPGE-2之间的相似性,AMD让UVD3完全支持MPEG-4 ASP硬件解码,AMD也很容易地让UVD3完全支持MPEG-2硬件解码,因为他们可以重新利用MPEG-4 ASP解码块来用在MPEG-2上。同理,UVD3完全支持MPEG-2硬件解码的意义,还是在于低端市场和产品,将CPU解放出来,同时降低低端产品功耗,延长电池使用时间等等。

3D内容的HDMI1.4a封包帧
UVD3另外一项新功能是支持多视点视频编码(MVC)。多视点视频编码本身不是什么新东西,而是H.264对应的3D立体扩展。H.264需要加以修订,来支持存储和传输3D立体视频所使用的封包帧格式。因此,AMD在UVD3当中加入对MVC的支持,让UVD3可以处理蓝光3D。
后,除了添加对新编解码器的支持和新的显示输出之外,Barts显示控制器也完善了色彩校正能力。Cypress的显示控制器也可以进行色彩校正,但是必须在Gamma校正完成之后,这意味着Cypress只能在非线性Gamma色彩空间当中进行色彩校正,颜色的准确性可能会受到损失。现在,Barts内建的显示控制器把图像从Gamma转换到线性色彩空间来进行线性空间的色彩校正,然后再将其转换回到Gamma色彩空间用于显示输出。
由于色彩校正大部分被用在广色域显示器上,因此Barts在处理色彩校正上的变换不会马上被大多数用户察觉。但是,随着广色域显示器的普及,色彩校正会变得越来越重要,因为广色域显示器的缺点就是会曲解正常的sRGB色彩空间,而绝大多数渲染正好是在正常的sRGB色彩空间当中完成。


{kind=link}
{kind=link}
{kind=link}